Summary
- DexterLab introduces a cutting-edge archival system for Solana blockchain, offering a more efficient, scalable, and cost-effective solution for managing historical data compared to existing methods like Google BigTable.
- Utilizing bare metal infrastructure and Kubernetes, DexterLab's approach significantly improves data accessibility and system performance, ensuring faster and more reliable access to extensive historical data on Solana.
- DexterLab's solution dramatically reduces operational costs by employing HDFS/HBase for robust data management and a data ingestion service that minimizes the impact on validator performance, offering a more affordable alternative to traditional cloud services.
- The introduction of a Light RPC client specifically for historical data allows for handling a high number of parallel requests efficiently, overcoming the limitations of standard RPCs and enhancing overall system responsiveness.
- DexterLab is committed to continuous improvement and innovation, with plans to transition to an open-source model by the end of the year, fostering greater community collaboration in blockchain data management.
In the dynamic world of blockchain technology, Solana distinguishes itself with unparalleled performance and scalability. As the network grows, so does the complexity of managing its historical data. This guide explores Solana historical data in detail, addressing today's issues, presenting new solutions, and imagining a future of effective data management on this robust platform.
Current State of Solana Archival Data
Google BigTable Integration: The primary method to access full Solana archival data is through validator integration with Google BigTable. Validators in a special mode work directly with BigTable to read and write a lot of historical data. While this system is strong, it makes it hard for more people to access the data because of its exclusivity and technical challenges.

Limitations of Regular RPCs: Standard RPCs provide a limited historical window, typically spanning only a few days. Some providers extend this range slightly, but it's still inadequate for in-depth analysis, particularly for long-term trend analysis and comprehensive network insights.
Decentralized Storage Initiatives: The Solana Foundation's 'old-faithful' project is trying to spread out where archival data is stored. This is a big move towards making the system stronger and less centralized. However, it's mainly used for backup and doesn't completely solve the problems of getting to and analyzing the data.
The Challenges of Historical Data on Solana
Restricted Access: The necessity for direct integration with Solana validators for comprehensive data access creates a significant barrier. This limited access makes it hard for independent developers, researchers, and analysts to explore the network's extensive history.
Data Accessibility and Readability: Current methods, like Google BigTable and standard RPCs, make it hard to access and analyze a lot of historical data. This issue makes it difficult to do detailed analysis of the network, which is important for understanding and improving Solana ecosystem.
Our Approach
Our solution is built on an open-source ethos, ensuring you can host it locally for optimal performance. Here are the five key ingredients of our approach:
Peak Efficiency and Control via Bare Metal Infrastructure
When building our archival system, we chose bare metal servers because they are really fast and cost-effective. This choice helps us avoid the high costs usually linked with cloud services. It also allows us to set up our servers in many places, from professional data centers to home setups.
The use of bare metal servers reflects our dedication to full infrastructural autonomy. This autonomy translates to a significant reduction in operational costs and an increase in performance reliability. Our commitment to this approach ensures that developers and users have access to a robust, high-performance data handling service that stands apart from cost-intensive cloud solutions.
Streamlined Service Management with Kubernetes
Leveraging Kubernetes is central to our architecture, particularly for orchestrating services that require efficient management and seamless scalability. Its proven capabilities are essential as the volume of historical data on the Solana blockchain expands. Kubernetes automates the deployment, scaling, and operations of application containers across clusters of hosts, which is fundamental in handling the increasing load without compromising on performance. This ensures our system remains resilient and adaptable, ready to grow alongside the ever-expanding Solana ecosystem.
Robust Data Management via HDFS/HBase
Our archival solution employs HDFS/HBase, an open-source framework that rivals Google BigTable in terms of robustness and manageability. HDFS (Hadoop Distributed File System) is designed to store large data sets reliably, and HBase offers real-time read/write access to those datasets. The compatibility with BigTable is a significant advantage, facilitating the seamless importation of backup files and integration with the existing Solana ecosystem.
By choosing HDFS/HBase, we capitalize on its time-tested performance and ease of management. It allows us to work with the current data structures and validator code from Solana with minimal adjustments, streamlining the transition to our system and reducing the need for extensive redevelopment. This strategic decision not only ensures reliability and efficiency but also accelerates the deployment of our archival services.
Scalable, Resilient Data Ingestion Service
Our data ingestion service, built from the Solana validator's original code, is designed for high scalability and minimal impact on validator performance. With the capability to handle a few 1,000 to 10,000 inserts per block, it adds only a modest 5-15% CPU load. For larger throughputs, the service operates independently, ensuring that validator resources are optimized and system integrity is maintained during peak loads.
This service processes data from diverse sources, including serialized binary streams and raw JSON blocks, efficiently offloading the validator. It also acts as a fail-safe, filling in data gaps during downtimes. Integral to this service is a sophisticated filtering mechanism that paves the way for selective data ingestion, aligning with our data split strategy for storage optimization and enhanced access speed.
Basically, our data ingestion service is designed to meet challenging data needs on Solana, offering a strong, efficient, and scalable way to manage blockchain data.
Light RPC for Archival Data
Usually, increasing RPC capacity means adding more validators, which can be very costly and not efficient. Our solution was to create a Light RPC client just for historical data. We made sure it works well with BigTable's data structure, so we could use the same code from the original validator for our client. The results speak for themselves:
- The Light RPC client operates on a lean 40-100MB of RAM.
- It allows us to launch hundreds of instances simultaneously.
- This enables us to handle an unprecedented number of parallel requests, far exceeding the capabilities of traditional setups.
The graphic below showcases the slowest RPC methods in terms of requests per second (RPS) with stable latency, underscoring the performance bottlenecks that our solution is designed to address.
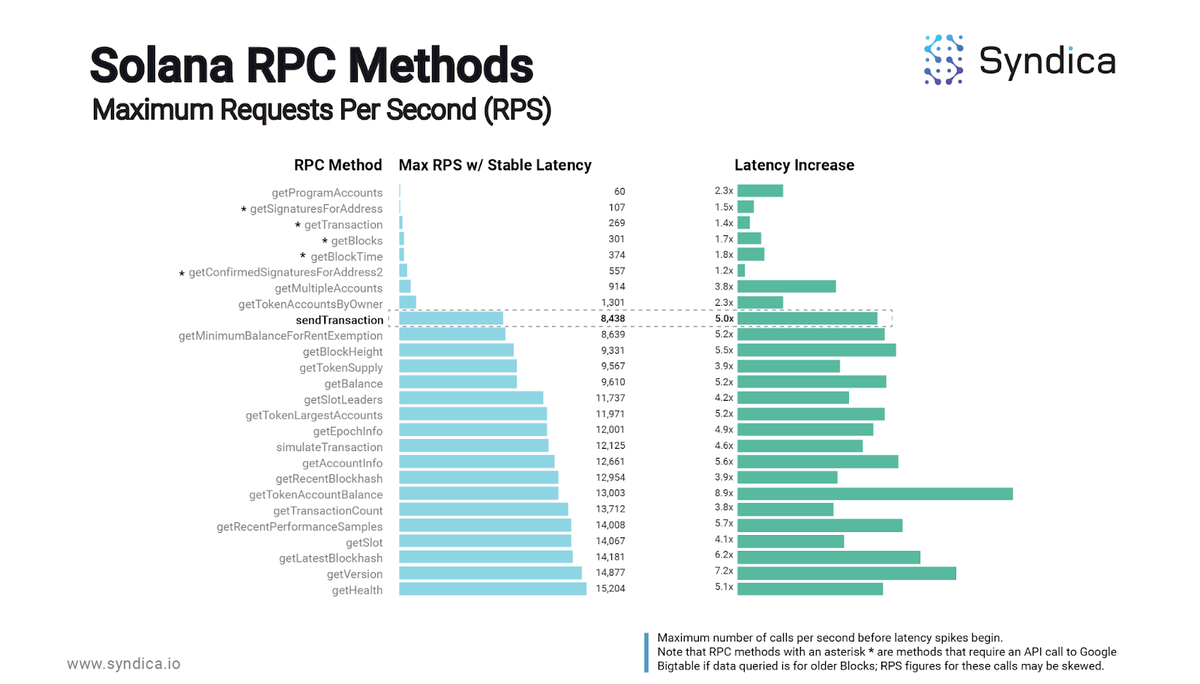
Note: The RPC methods marked with an asterisk are those that require an API call to Google BigTable. The RPS figures for these methods may be skewed when the data queried is for older blocks.
By optimizing these slow-performing RPC methods, our Light RPC client enhances overall system responsiveness and significantly reduces the operational costs associated with Solana archival data retrieval.
Comparative Analysis
Combining open-source components with our custom-designed services has led to significant cost savings and better performance for managing Solana archival data.
Emphasizing Cost Efficiency
Our goal to be more cost-effective has been about reducing operation costs without lowering service quality. We use machines with 2-3 hard drives (HDDs), each 12-16TB, costing about 110 USD each. This setup gives us a lot of storage space and the advantage of unlimited data transfer inside our system, which is really useful for the heavy data work common in blockchain technology.
Moreover, our infrastructure design includes a generous allowance for outgoing traffic. Despite the high volume of data that blockchain operations typically handle, our system architecture ensures that it's a rare occurrence to hit these traffic ceilings. This shows how cost-effective our solution is, providing a cheaper option compared to the costly, pay-as-you-go pricing of services like Google BigTable.
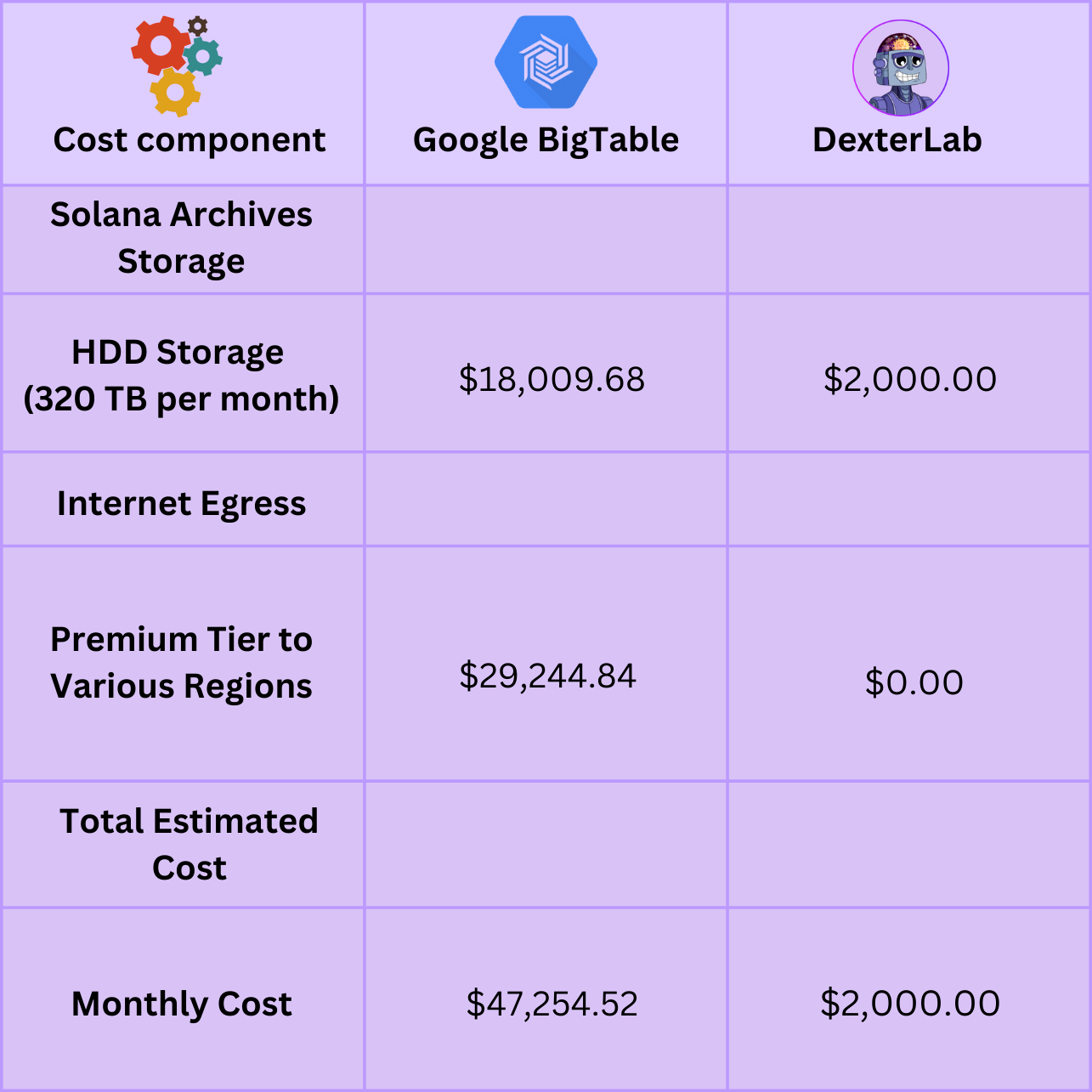
The DexterLab solution presents a cost-effective alternative, with significant savings for both storage and data transfer.
Savings Breakdown:
For raw storage costs with minimal access, DexterLab offers a tenfold cost reduction, turning an $18,000 expense into just $2,000.
With DexterLab, the cost of internet egress, which amounts to over $29,000 on Google Cloud, is entirely mitigated to $0.
When factoring in real-world traffic load and data access patterns, the savings can be even more pronounced, with up to a 20x reduction in costs compared to the BigTable solution.
DexterLab's innovative approach to data storage eliminates expensive IOPS charges and egress fees by utilizing bare metal solutions.
Optimal Performance with Localized Solutions
Performance is where our solution truly shines. While integrating our Light RPC client with BigTable was an option, it would not have given us the performance leap we desired due to the inherent latency from multiple network hops. Instead, we chose a different path. Our architecture allows us to deploy our solution in close proximity to the user's operational environment, drastically reducing latency to achieve response times consistently in the range of 10-20ms.
This localized approach not only enhances performance but also provides a more resilient and reliable service. By hosting our solution near the user's codebase, we ensure that the data is rapidly accessible, minimizing delays and maximizing the efficiency of data-driven operations on the Solana blockchain.
The graphic provided shows DexterLab's Light RPC client handling the getSignaturesForAddress call efficiently. This call is usually slow for older blocks because it requires BigTable, but it's vital for developers in Solana ecosystem. Our single-thread request tests, running requests one by one, show DexterLab client is faster than others, offering quick response times for this essential call.
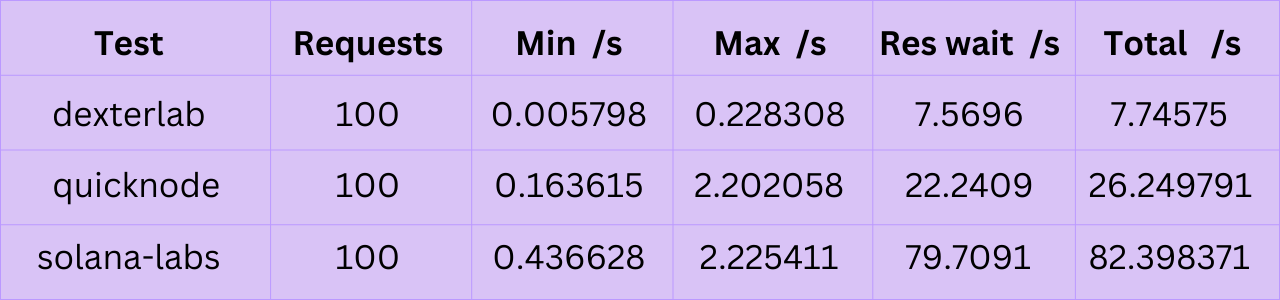
Disclaimer: Our full archive is currently deployed only in the EU. Expansion to Asia and the US is planned for the first quarter of 2024. However, for those needing to handle numerous concurrent requests, the benefits of our system's concurrency will effectively compensate for any latency due to ping differences.
DexterLab is improving speed within Solana data services, ensuring developers have quick and reliable access to important historical data, even when dealing with calls that are typically slower.
Continuous Improvement and Innovation
We are always working to make data management on Solana better. We don't stop or settle for what we have achieved; instead, we keep looking for new ways to make it faster and more portable.
Future enhancements are already on the drawing board. We aim to implement advanced data handling techniques that will further streamline the access and processing of rich datasets on Solana. These improvements will not only boost the speed of data retrieval but will also enhance the portability of the entire archival system, making it even more accessible to users regardless of their location or scale of operation.
By advancing these initiatives, we are dedicated to delivering a better solution that fits the Solana community's growing needs and improves how blockchain data is managed.
Data Management Efficiency via Data Split
Much of Solana archival data includes information that developers rarely need. During the ingestion phase, we have the capability to filter out specific programs. For example, by ignoring the system program in the secondary index – which is responsible for a substantial amount of data (approximately 10TB) – we can greatly reduce the size of our archives. Early studies show we might be able to reduce the archival data by about 80%, but still keep all the important data for developers.
Real-Life Example of Data Split Efficiency
The "tx-by-addr" table's large data size, primarily used for transaction tracking by address, is not frequently required in active queries by developers.
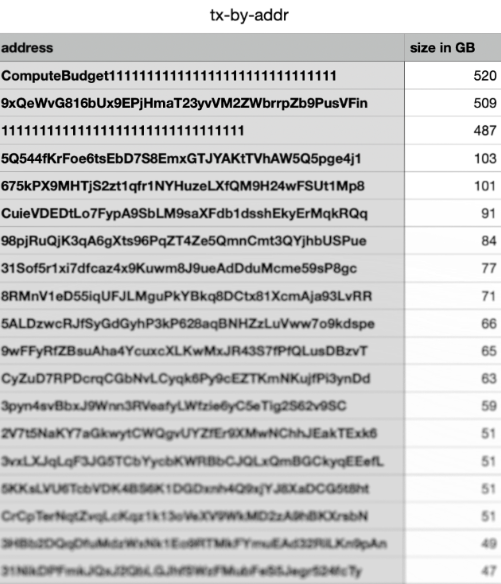
Migrating this bulky data to cold storage optimizes resource usage, as the primary users of such a table—blockchain scanners—do not require instant access for their operations.
This strategic data placement facilitates a leaner active database, resulting in faster access times for frequently used data and significant cost savings, illustrating the practical benefits of data splitting.
Enhanced Accessibility and Performance via Data Duplication
A crucial aspect of our approach is Data Duplication. Given the substantial savings we have achieved in hosting costs compared to using Google BigTable, We are now ready to use more advanced data duplication methods without worrying about higher costs.
Current Process Challenges
Currently, retrieving a transaction requires the RPC server to perform a multi-step process:
- Lookup: The server first looks up the transaction block in one of the archival tables.
- Download: It then downloads the entire block from a different table.
- Find and Return: Finally, the server finds and returns the specific transaction in the block.
This process adds a significant load to the network, which was likely an initial design decision to minimize storage costs.
Our Improved Approach
Our solution involves duplicating blocks and transactions, thereby streamlining this process:
Separate Non-Vote Transactions: By writing non-vote transactions to a separate table, we can significantly improve the responsiveness of the getTransaction call.
Enhanced Accessibility: Along with improved capacity, this separate table allows for more innovative functionalities. For example, we can introduce a feature that retrieves all transactions executed by a specific wallet. This is similar to the getSignatures function, but it would show complete transactions with the right date filters.
This strategy not only enhances the performance and responsiveness of data retrieval but also introduces new possibilities for accessing transaction data, making our solution more flexible and user-friendly.

Our archival system's structure is designed for efficiency and speed. Here’s how we are enhancing it:
- Blocks (~50TB): This is where raw, unserialized blocks are stored. It forms the core of our data, encompassing the entire ledger history.
- Transactions (tx) (~30TB): This index lists all transactions and includes pointers to their respective blocks. It's a vital reference point for navigation within the blockchain.
- Transactions by Address (tx-by-addr) (~120TB): Specifically used to retrieve signature lists for particular addresses. While extensive, not all of this data needs to be at the fingertips of developers and can be stored more cost-effectively.
We are extending this system with:
- Transactions by Signature (tx-by-sig): By duplicating certain data elements, we enable direct access to full transaction payloads via the transaction signer. This eliminates the need for retrieving signatures and parsing transactions individually, providing all necessary data in one request.
Data duplication is one example; we will unveil more such cases soon.
Access our Solutions Today!
Access through DexterLab OG NFTs: DexterLab OG NFT holders currently have exclusive access to our solutions via a dedicated Developer Portal. This exclusivity phase is crucial for fine-tuning our system with real-world use cases and feedback.
For custom solutions connect with us via Telegram
Open-Source Transition Plan: In line with our commitment to the Solana community, we plan to transition our solutions to an open-source model by the end of the year, fostering community collaboration and innovation.
Conclusion
Our new, open-source, self-run system is a big step forward in handling historical data on Solana. Using advanced techniques, we overcome the problems of current systems, offering a scalable, efficient, and high-performance way to access and study Solana historical data. This effort aims to fully use the network's capabilities, helping us better understand its development and influence its future direction.